模型精度测试
关于模型精度测试
模型精度测试定义
- 功能描述:模型精度测试旨在验证用户基于本文档编写的自定义推理在特定数据集上的预测准确率。
- 要求:模型推理服务需支持流式接口/v1/chat/completions方式访问
如何进行模型精度测试
- 遵循下文模型精度测试运行脚本的指导编写脚本。注意:只有模型适配仓库管理员并且仓库硬件类型为npu,才可以发起模型精度测试。

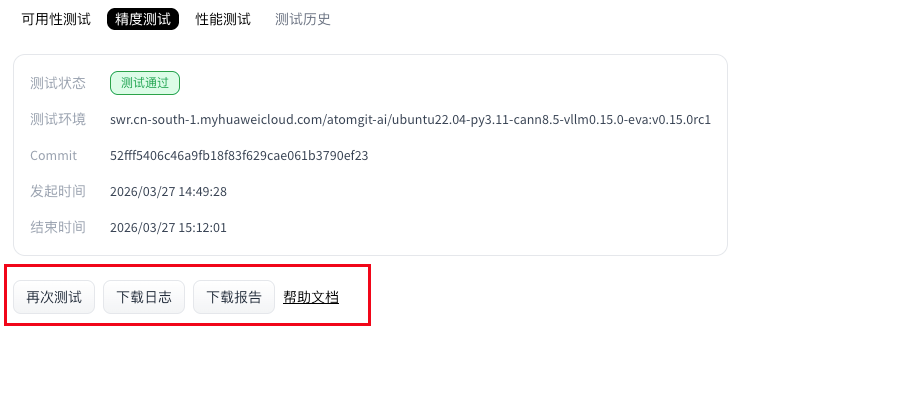
- 点击模型评测tab栏,进入模型评测页面。
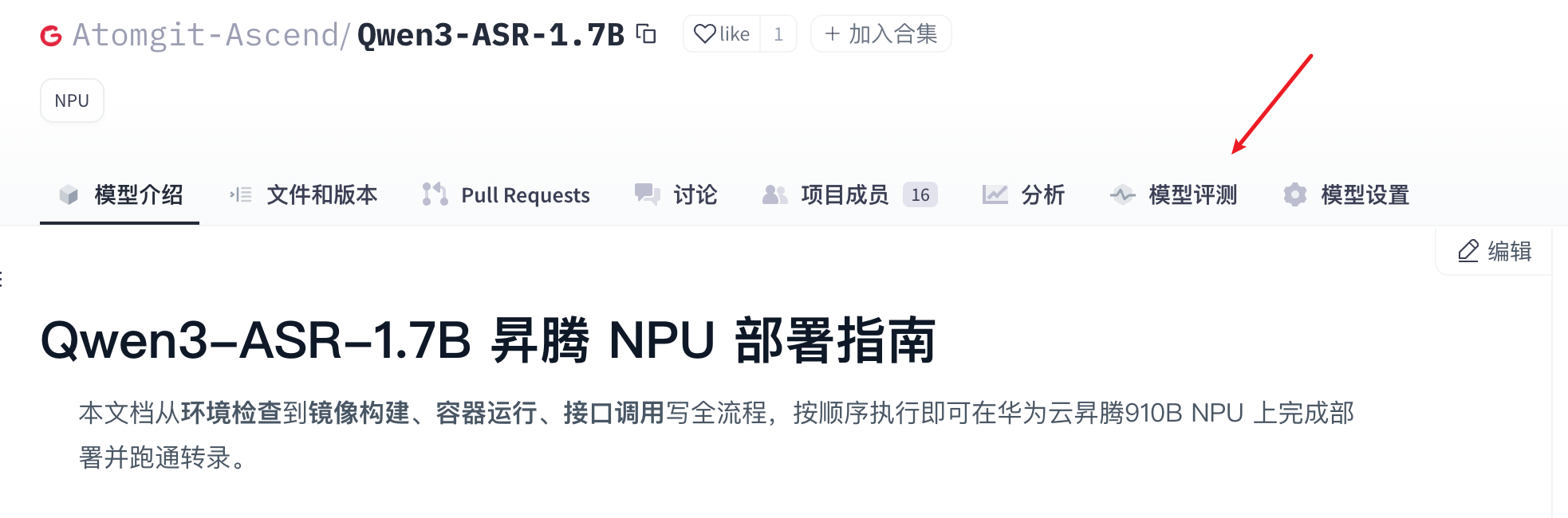
- 在模型精度评测页面,点击“精度测试”的tab,选择模型的权重文件仓库,然后单击“立即测试”,发起精度测试。
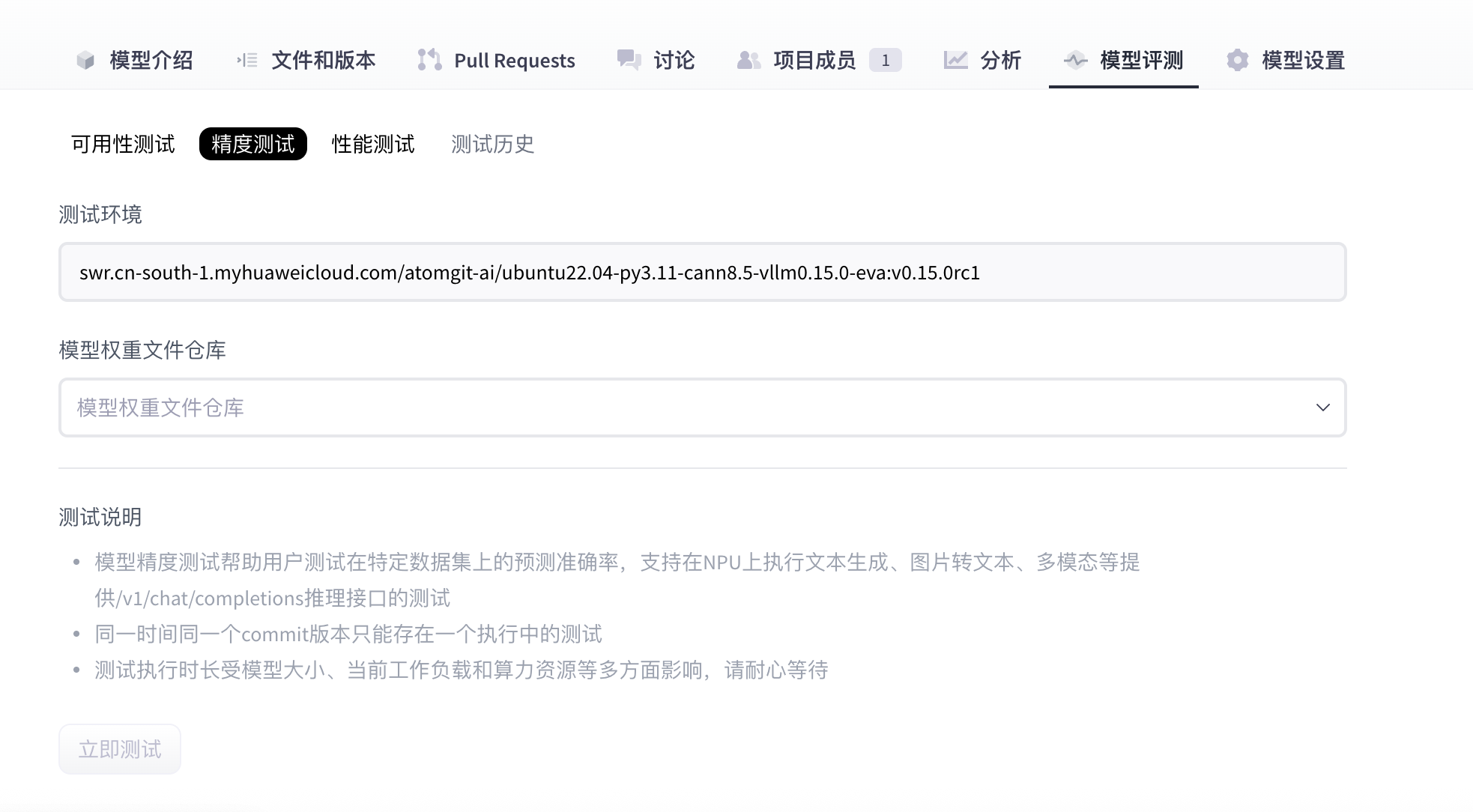
- 等待精度测试执行完成。
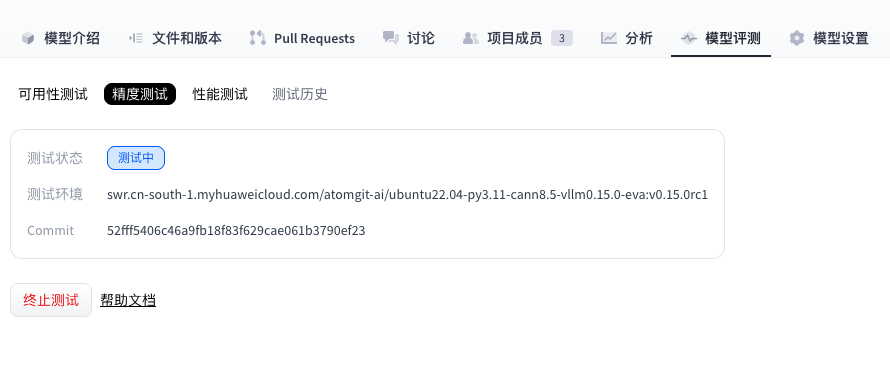
- (可选) 当精度测试处于“测试中”时,用户可以单击“终止测试”手动停止测试。
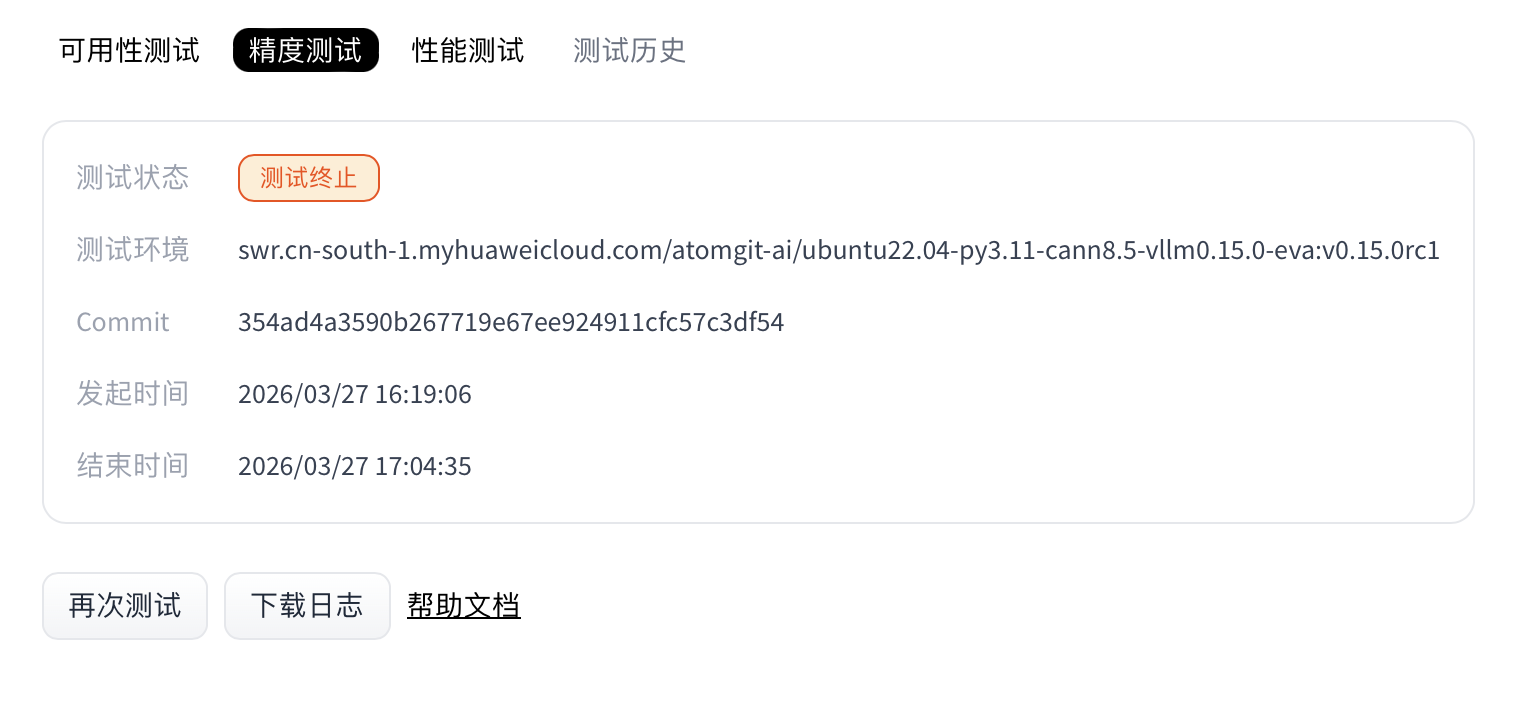
- 当精度测试完成后,在“精度测试”区域显示测试状态,并提供测试日志和评测报告下载。
模型精度测试运行脚本
模型精度测试脚本以deploy.sh为入口。脚本编写请严格遵照本文档的规范。
模型精度测试的适配仓库须包含以下文件:
- requirements.txt:该脚本运行需配置的相应module ,如果没有需要安装的依赖,则无需创建 (非必须)。
- deploy.sh: 模型评测服务基于该脚本安装依赖和启动此模型适配项目 (必须)。
文件位置
requirements.txt和deploy.sh必须位于仓库根目录下。
requirements.txt文件(可选)
请设置NPU下运行该脚本需要配置的对应依赖,Torch_npu、Cann和Python根据选择的框架版本由环境提供,因此在requirements.txt中不需要重复上述依赖的添加(可能会导致依赖安装冲突异常)。库的依赖脚本格式示例如下:
transformers==4.37.0
accelerate==0.27.2
如果不需要添加任何依赖,该.txt文件可不提供,测试任务会跳过依赖安装。
deploy.sh文件
该文件是一个执行启动模型适配推理的shell脚本,该推理脚本运行方式无严格限制,以下为脚本规范。
执行安装依赖编写示例(可选)
python3 -m pip install --upgrade pip setuptools wheel
构造执行脚本所需要的入参
模型权重由自动化测试执行侧根据模型精度测试发起时页面选择模型权重仓库,在执行测试的时候下载。在shell脚本中,如果需要传入权重路径,可以通过环境变量"$MODEL_PATH"获取权重文件所在的path路径。如vllm启动项目,则传入模型path路径示例如下:
vllm serve "$MODEL_PATH" --trust-remote-code --tensor-parallel-size 1 --dtype float16 --max-num-seqs 4 --gpu-memory-utilization 0.95
适配代码编写要求
适配推理代码需要提供标准的openapi推理接口,并且启动http server服务的端口必须为:8000。模型评测服务会根据选择的模型权重文件任务类型调用对应的推理接口进行模型精度测试,目前已经支持评测任务类型如下:
| 任务类型 | 任务编码 | 推理接口path |
|---|---|---|
| 文本生成 | text-generation | /v1/chat/completions |
| 图片转文本 | image-text-to-text | /v1/chat/completions |
| 多模态 | any-to-any | /v1/chat/completions |
注:模型精度测试服务依赖请求/v1/chat/completions进行测试,如果不存在此推理接口,会导致精度评测任务失败。
模型权重文件大小限制
- 大小上限:100GB
- 限制说明:适配模型权重文件存储大小不得超出上限。
- 影响范围:若超出限制,将触发模型权重文件下载失败,直接导致模型精度测试任务失败。
全流程代码示例
deploy.sh
- vllm适配验证示例:
#!/bin/sh
set -e
echo "=== MODEL_PATH set to: $MODEL_PATH ==="
vllm serve "$MODEL_PATH" --trust-remote-code --tensor-parallel-size 1 --dtype float16 --max-num-seqs 4 --gpu-memory-utilization 0.95
注:上面示例为vllm启动方式,无需设置–served-model-name,模型评测服务会自动使用模型权重的path作为serverd-model-name.
精度测试报告
精度评测执行成功以后,下载精度测试报告,解压缩以后,包含以下文件夹:configs、predictions、results、summary,
最终生成的目录结构如下:
ee9480acbbac4d4aa190a124d5ddf39c/
├── configs # 模型任务、数据集任务和结构呈现任务对应的配置文件合成的一个配置
│ └── 20260326_151326_29317.py
├── logs # 执行过程中日志,命令中如果加--debug,不会有过程日志落盘(都直接打印出来了)
│ ├── eval
│ │ └── vllm-api-general-chat
│ │ └── demo_gsm8k.out # 基于predictions/文件夹下的推理结果的精度评测过程的日志
│ └── infer
│ └── vllm-api-general-chat
│ └── demo_gsm8k.out # 推理过程日志
├── predictions
│ └── vllm-api-general-chat
│ └── demo_gsm8k.json # 推理结果(推理服务返回的所有输出)
├── results
│ └── vllm-api-general-chat
│ └── demo_gsm8k.json # 精度评测计算的原始分数
└── summary
├── summary_20260326_151326.csv # 最终精度分数呈现(表格格式)
├── summary_20260326_151326.md # 最终精度分数呈现(markdown格式)
└── summary_20260326_151326.txt # # 最终精度分数呈现(文本格式)
summary文件夹下中summary_20260326_151326.md的内容展示如下:
| dataset | version | metric | mode | vllm-api-stream-chat |
|---|---|---|---|---|
| demo_gsm8k | 0ba9da | accuracy (5 runs average) | gen | 5.60 |
| demo_gsm8k | 0ba9da | avg@5 | gen | 5.60 |
| demo_gsm8k | 0ba9da | pass@5 | gen | 24.00 |
| demo_gsm8k | 0ba9da | cons@5 | gen | 0.00 |
精度测试结果说明
一、计算公式中 n 、k 与API配置文件中 num_return_sequences 的三者关系
1. pass@k的计算逻辑
此处仅简要描述pass@k一个指标作为参考,其它指标计算公式请参考pass@k, cons@k, avg@n 的定义与关系
pass@k是代码生成任务的核心评估指标,用于衡量模型在生成k个候选解时,至少有一个解能通过所有测试用例的概率。其计算采用无偏估计方法,避免直接采样导致的方差问题。具体逻辑如下:
生成样本与正确性统计:
- 对每个问题生成
n个候选解(n ≥ k),其中c个解通过测试(即功能正确)。 - 例如:生成
n=100个样本,其中c=20个正确,则单样本通过率。
- 对每个问题生成
组合数学公式:
- 计算从
n个样本中随机抽取k个样本时,全部失败的概率:
pass@k为至少一个成功的概率:
- 优化计算:为避免阶乘溢出,代码实现使用数值优化:
pass@k = 1 - np.prod(1.0 - k / np.arange(n - c + 1, n + 1))- 计算从
无偏估计的意义:
在当前实现中,
k和n暂时仅支持通过num_return_sequences配置为相同的值,故此处仅探讨无偏估计实现的优势直接采样
k次会导致高方差(尤其当k较大时),而生成n(n >> k)个样本后通过组合公式估算,显著提升统计稳定性。 示例:若n=5,c=3,k=2:全部失败概率 =
C(2,2)/C(5,2) = 1/10 = 0.1pass@2 = 1 - 0.1 = 0.9(即90%概率在2次尝试中至少成功一次)。
2. 参数中的n、k与num_return_sequences的关系
三者均需为正整数,精度测试服务中
num_return_sequences默认为:5。
| 是否支持配置 | 参数 | 解释 | 定义位置 | 约束关系 |
|---|---|---|---|---|
| 否 | n | 副本数(即每个问题生成n个副本),也叫作总生成样本数 | 目前不支持单独配置,取值为num_return_sequences | 需满足:n ≥ k,但当前实现不支持单独配置,故无需关注 |
| 否 | k | 评估时随机抽取的样本数,决定pass@k的抽样规模 | 目前不支持单独配置,取值为num_return_sequences | 需满足:n ≥ k,但当前实现不支持单独配置,故无需关注 |
| 是 | num_return_sequences | 单条请求独立重复推理次数 | API模型配置文件,默认为5 | - |
3. 总结
- pass@k逻辑:基于组合数学的无偏估计,解决直接采样的高方差问题。
- 当前实现的计算逻辑中的参数关系与约束:
n和k目前不支持单独配置,仅num_return_sequences可在API配置文件中指定n=k= num_return_sequencespass@k、cons@k和avg@n名称中的k或n均为num_return_sequences
由于n和k虽然仅在评估阶段用于指标计算,而num_return_sequences用于推理过程,但取值来自于API配置文件中的num_return_sequences,所以在执行评估阶段(–mode eval)时,请确保reuse的推理结果中,配置的num_return_sequences与当前num_return_sequences值保持一致。
二、pass@k, cons@k, avg@n 的定义与关系
1. 背景介绍
在大语言模型和多模态理解强化学习评估中,pass@k、cons@k 和 avg@n 是三个核心指标,用于从不同维度衡量模型在多次推理中的表现。这些指标适用于代码生成、数学推理、强化学习等需要多次独立推理的任务场景,提供对模型性能的统计学意义上的多维度评估。
2. 指标定义与计算
2.1 指标定义
指标数学定义:
pass@k:
$$ 1 - \prod_{j=n-c+1}^{n} (1 - \frac{k}{j}) $$ cons@k:
$$ \frac{1}{N} \sum_{i=1}^{N} I(c_i > k/2) $$ avg@n:
$$ \frac{1}{N} \sum_{i=1}^{N} \frac{c_i}{n} $$| 指标 | 计算逻辑 | 评估目标 | 值域 |
|---|---|---|---|
| pass@k | 至少一次正确的概率(无偏估计) | 模型解决能力的可靠性 | [0, 1] |
| cons@k | 多数正确的概率估计 | 输出结果的稳定性 | [0, 1] |
| avg@n | 平均样本正确率 | 预测结果的整体准确性 | [0, 1] |
其中:
- N: 问题总数(即数据集中问题的数量)。
- n: 每个问题的重复推理次数(总生成样本数),对应于代码中的 n 参数。
- k: 评估抽样数,用于计算 pass@k 和 cons@k,对应于代码中的 k 参数。
- cᵢ: 问题 i 的正确次数(即该问题中通过测试的样本数量)。
- I(·): 指示函数(条件满足为1,否则为0)。
- 公式中的乘积项索引 j 从 n-c+1 到 n,确保数值稳定性。
2.2 计算逻辑详解
- pass@k:基于无偏估计方法,避免直接采样的方差问题。代码中使用
compute_pass_at_k(n, c, k)函数计算,其中n是每个问题的总样本数,c是正确样本数,k是抽样数。公式等价于组合数学形式 ,但采用乘积形式优化计算。 - cons@k:表示模型输出的“一致性”或“稳定性”,即多数样本正确的比例。代码中对于每个问题,如果正确样本数 超过 ,则计为1,否则计为0,然后在所有问题上取平均。这直接反映了多数投票的准确率。
- avg@n:表示所有问题的平均样本级别准确率。代码中对于每个问题计算
c / n(正确率),然后在所有问题上取平均。这反映了模型预测的整体准确性。
2.3 计算示例(num_return_sequences=3,即n、k = 3)
问题1:预测 [A, A, X] → 正确次数=2
问题2:预测 [B, C, B] → 正确次数=2
问题3:预测 [X, X, C] → 正确次数=1
问题4:预测 [X, X, X] → 正确次数=0
pass@3 = (1.0 + 1.0 + 1.0 + 0.0)/4 = 0.75(问题1、2、3至少一次正确,问题4没有)
avg@3 = (2/3 + 2/3 + 1/3 + 0/3)/4 = (0.6667 + 0.6667 + 0.3333 + 0.0)/4 ≈ 0.4167
cons@3 = (1 + 1 + 0 + 0)/4 = 0.5(问题1和2多数票正确,问题3和4不正确)
3. cons@k vs avg@n
3.1 大小关系分析
由于统计学意义上的定义,pass@k总是大于或等于 avg@n和 cons@k,不可能存在 pass@k小于其他两个指标的情况,故此处不比较pass@k与其它两个指标
cons@k和avg@n的大小关系不确定,主要取决于模型预测的模式。以下是几种常见情况:
情况一:cons@k > avg@n
- 场景:模型预测倾向于高度一致但非完全正确(即多数问题有严格多数票正确,但正确率不是100%)。
- 示例:设
k=3,有 2 个问题:- 问题1:预测
[A, A, B],真实答案A→ 正确次数 2,正确率 2/3 ≈ 0.667;多数票正确(A出现 2 次 > 1.5),所以cons贡献 1。 - 问题2:预测
[B, B, C],真实答案B→ 正确率 2/3 ≈ 0.667;多数票正确,cons贡献 1。 avg@n= (0.667 + 0.667) / 2 = 0.667cons@k= (1 + 1) / 2 = 1.0- 因此
cons@k>avg@n。
- 问题1:预测
情况二:cons@k < avg@n
- 场景:模型预测分散,没有多数票,但平均正确率较高(即正确预测均匀分布,但缺乏一致性)。
- 示例:设
k=3,有 2 个问题:- 问题1:预测
[A, B, C],真实答案A→ 正确次数 1,正确率 1/3 ≈ 0.333;无严格多数票(所有出现次数 ≤ 1.5),所以cons贡献 0。 - 问题2:预测
[A, B, C],真实答案B→ 正确率 1/3 ≈ 0.333;无严格多数票,cons贡献 0。 avg@n= (0.333 + 0.333) / 2 = 0.333cons@k= (0 + 0) / 2 = 0- 因此
cons@k<avg@n。
- 问题1:预测
情况三:cons@k ≈ avg@n
- 场景:模型预测几乎完美或完全错误,或者预测分布使得多数票正确率与平均正确率相近。
- 示例:设
k=3,有 2 个问题:- 问题1:预测
[A, A, A],真实答案A→ 正确率 1.0;多数票正确,cons贡献 1。 - 问题2:预测
[B, B, B],真实答案C→ 正确率 0.0;多数票错误,cons贡献 0。 avg@n= (1.0 + 0.0) / 2 = 0.5cons@k= (1 + 0) / 2 = 0.5- 因此
cons@k=avg@n。
- 问题1:预测
3.2 一般趋势
- 当模型预测高度一致(即多数问题有严格多数票正确)时,
cons@k可能高于avg@n,因为cons@k只要求多数票正确,而avg@n受错误预测拖累。 - 当模型预测分散(即多数问题无严格多数票)但正确率平均较高时,
avg@n可能高于cons@k,因为avg@n奖励部分正确,而cons@k要求多数票正确。 - 在理想情况下(所有预测正确或所有预测错误),两者相近。
- 在实际应用中(如强化学习场景下的多轮推理),
cons@k通常用于评估稳定性,而avg@n评估整体准确性。两者互补,没有固定大小关系。
4. 总结与建议
指标选择原则
- 优先
pass@k评估模型潜力 - 用
cons@k验证稳定性 - 用
avg@n衡量整体性能
- 优先
常见解读误区
- 仅关注
pass@1:忽略模型多次尝试的潜力 - 忽视
cons@k:可能导致生产环境不稳定 - 单独使用
avg@n:无法区分一致性和容错性
- 仅关注
指标应用与决策指导
以下阈值均为假设定义:高(>0.8), 中(0.5-0.8), 低(<0.5) 以下决策相关内容仅作参考
应用场景推荐
场景类型 核心指标 辅助指标 目标值 可靠性优先(医疗诊断、金融分析) cons@k pass@k cons@k > 0.8, pass@k > 0.9 容错性优先(代码生成、探索任务) pass@k avg@n pass@k > 0.8, avg@n > 0.7 平衡评估(通用AI助手) avg@n cons@k + pass@k avg@n > 0.75 决策指导矩阵
指标组合 模型状态 改进方向 高pass@k, 中avg@n, 低cons@k 潜力大但稳定性差 增强一致性(温度惩罚、投票机制) 中pass@k, 中avg@n, 中cons@k 均衡但需提升 全面优化(数据增强、提示工程) 低pass@k, 低avg@n, 高cons@k 系统性偏差 检查数据/提示工程/模型偏差 低pass@k, 低avg@n, 低cons@k 几乎失效 重新训练或更换模型架构
通过综合使用这三个指标,可以较为全面评估大语言模型的性能特征,为模型优化和应用部署提供具有统计学意义的科学依据。
5. 注意事项
当前并非所有数据集配置文件采用的评估器(Evaluator)支持这三种指标的计算,当数据集配置文件中eval_cfg指定的Evaluator未实现返回计算所需的指标时,则结果显示回退到仅计算原始用于精度表示的指标。
注:以上精度测试结果说明资料来源: AISBench官网