模型可用性测试
模型可用性测试定义
模型可用性测试旨在验证用户基于本文档编写的自定义推理用例在NPU上执行是否通过。
如何进行模型可用性测试
- 遵循下文模型可用性测试运行脚本的指导编写脚本。注意:只有模型适配仓库管理员并且仓库硬件类型为npu,才可以提交模型可用性测试申请。

- 点击模型评测tab栏,进入模型评测页面。
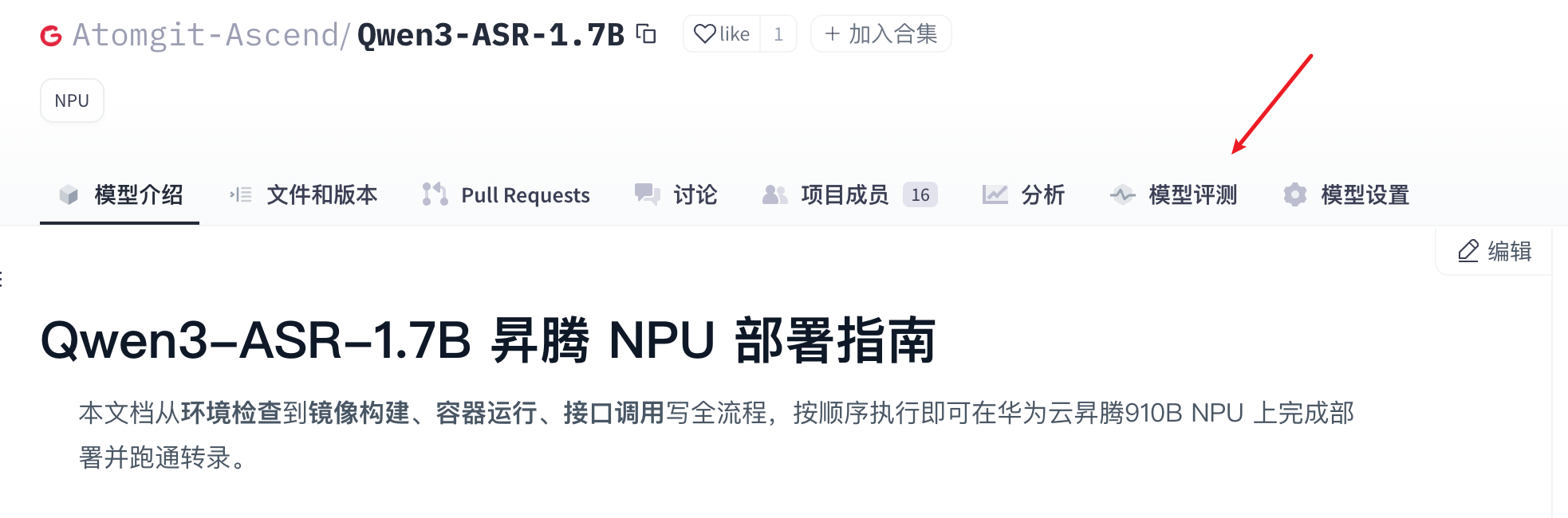
- 在模型评测的页面,点击“可用性测试”的tab,选择模型的权重文件,然后单击“立即测试”,就可以发起测试。
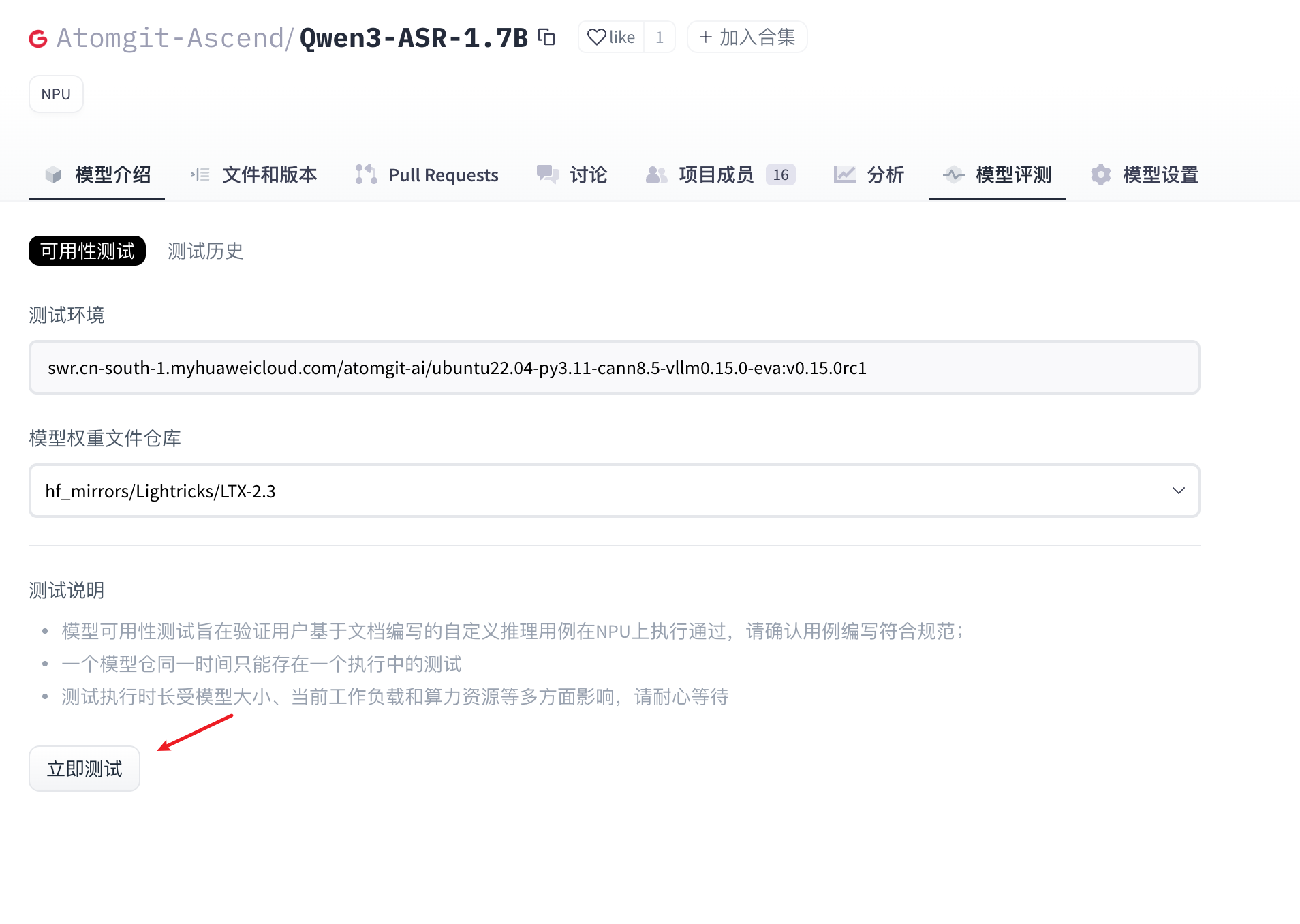
- 等待模型可用性测试用例执行完成。
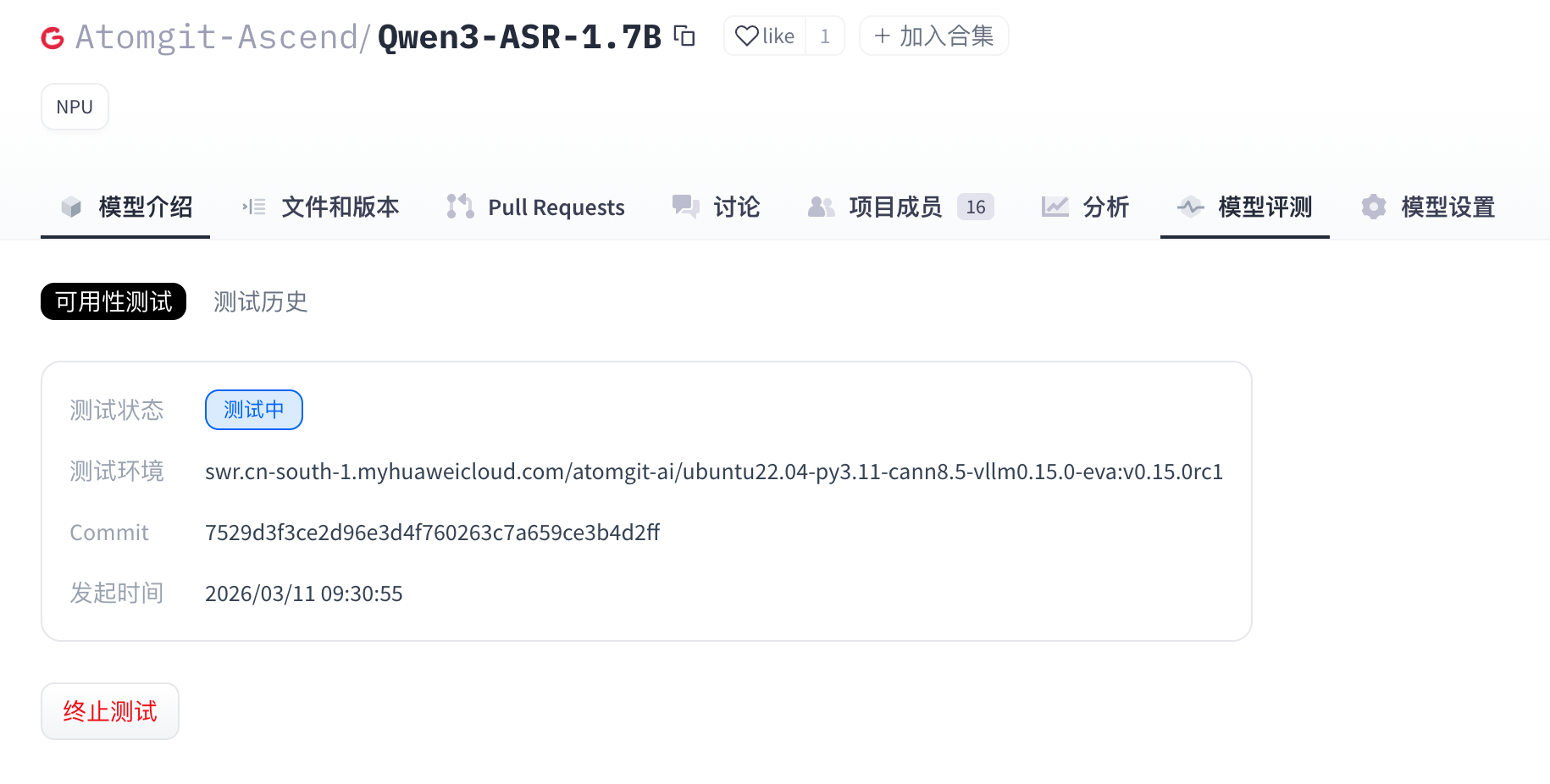
- (可选) 当模型处于“测试中”时,用户可以单击“终止测试”手动停止测试。
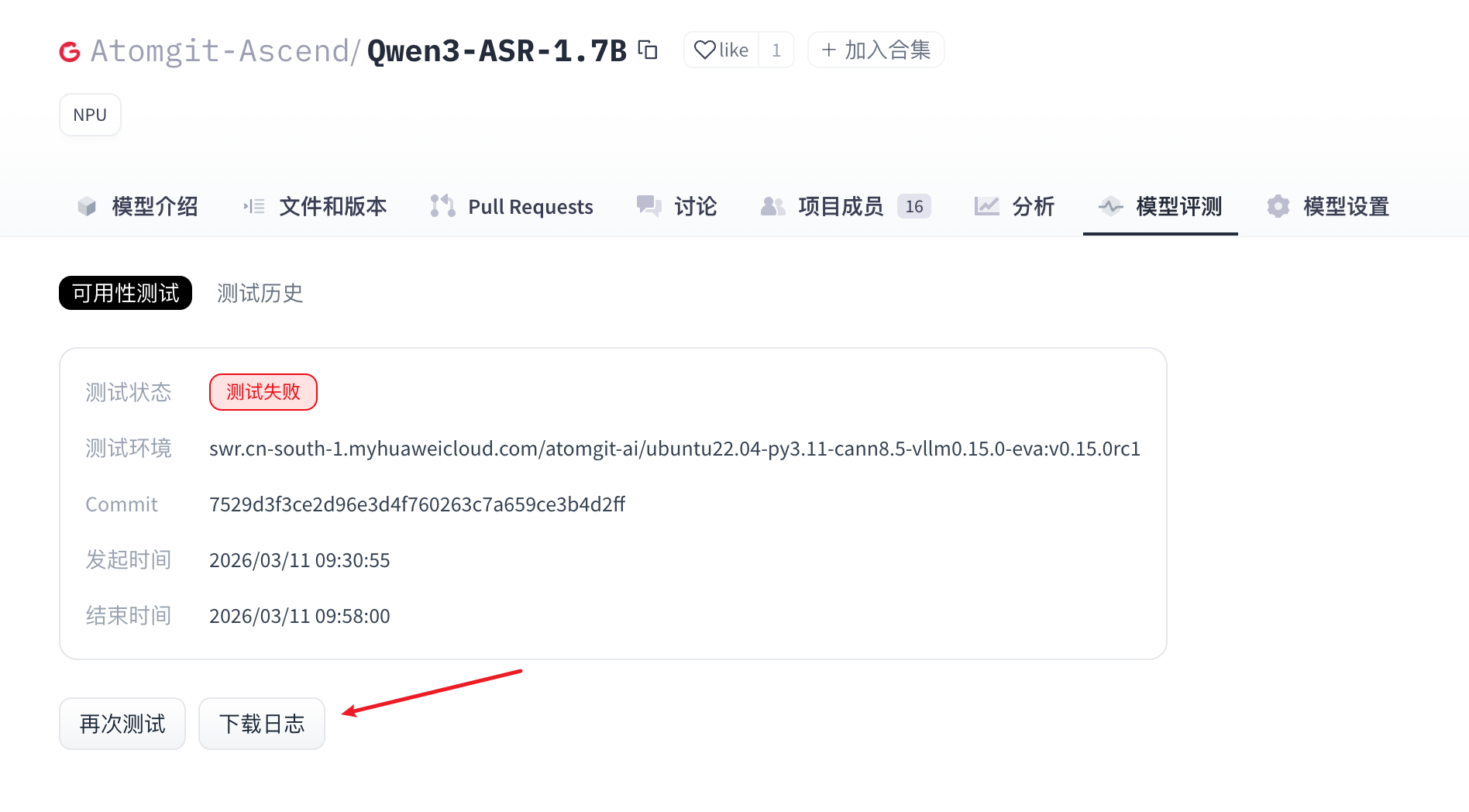
- 当模型评测完成后,在“可用性测试”区域显示执行结果。同时提供日志下载和测试结果查看。
模型可用性测试运行脚本
模型可用性测试脚本以deploy.sh为入口。脚本编写请严格遵照本文档的规范。
模型可用性测试脚本必须包含以下两个文件:
- requirements.txt:该脚本运行需配置的相应module (如果没有需要安装的依赖,则无需创建)。
- deploy.sh: 模型评测服务基于该脚本安装依赖和启动此模型适配项目。
文件位置
requirements.txt和deploy.sh必须位于examples根目录下。
- examples文件夹路径:位于根目录下
- requirements.txt路径:examples/requirements.txt
- deploy.sh 路径: examples/deploy.sh
requirements.txt文件(可选)
请设置NPU下运行该脚本需要配置的对应依赖,Torch_npu、Cann和Python根据选择的框架版本由环境提供,因此在requirements.txt中不需要重复上述依赖的添加(可能会导致依赖安装冲突异常)。库的依赖脚本格式示例如下:
transformers==4.37.0
accelerate==0.27.2
如果不需要添加任何依赖,该.txt文件可不提供,测试任务会跳过依赖安装。
deploy.sh文件
该文件是一个执行启动模型适配推理的shell脚本,该推理脚本运行方式无严格限制,以下为脚本规范。
执行安装依赖编写示例(可选)
python3 -m pip install --upgrade pip setuptools wheel
构造执行脚本所需要的入参
模型权重由自动化测试执行侧根据模型评测发起时页面选择模型权重仓库,在执行测试的时候下载。在shell脚本中,如果需要传入权重路径,可以通过环境变量"$MODEL_PATH"获取权重文件所在的path路径。如vllm启动项目,则传入模型path路径示例如下:
vllm serve "$MODEL_PATH" --trust-remote-code --tensor-parallel-size 1 --dtype float16 --max-num-seqs 4 --gpu-memory-utilization 0.95
适配代码编写要求
适配推理代码需要提供标准的openapi推理接口,并且启动http server服务的端口必须为:8000。模型评测服务会根据选择的模型权重文件任务类型调用对应的推理接口进行模型评测 目前已经支持评测任务类型如下:
| 任务类型 | 任务编码 | 推理接口path |
|---|---|---|
| 文本生成 | text-generation | /v1/chat/completions |
| 图片转文本 | image-text-to-text | /v1/chat/completions |
| 文本转语音 | text-to-speech | /v1/audio/speech |
| 多模态 | any-to-any | /v1/chat/completions |
| 语音识别 | automatic-speech-recognition | /v1/audio/transcriptions |
| 向量化 | embedding | /v1/embeddings |
注:如果适配框架为vllm启动方式,则可以忽略此条规则,因为vllm框架已经按照openapi规范提供标准推理接口。
模型权重文件大小限制
- 大小上限:100GB
- 限制说明:适配模型权重文件存储大小不得超出上限。
- 影响范围:若超出限制,将触发模型权重文件下载失败,直接导致模型评测任务失败。
全流程代码示例
deploy.sh
- vllm适配验证示例:
#!/bin/sh
set -e
echo "=== MODEL_PATH set to: $MODEL_PATH ==="
vllm serve "$MODEL_PATH" --trust-remote-code --tensor-parallel-size 1 --dtype float16 --max-num-seqs 4 --gpu-memory-utilization 0.95
注:上面示例为vllm启动方式,无需设置–served-model-name,模型评测服务会自动使用模型权重的path作为serverd-model-name.