模型性能测试
关于模型性能测试
模型性能测试定义
- 功能描述:模型性能测试旨在评估模型推理服务在真实部署环境中的运行效率(吞吐、延迟)
- 要求:模型推理服务需支持流式接口/v1/chat/completions方式访问
如何进行模型性能测试
- 遵循下文模型性能测试运行脚本的指导编写脚本。注意:只有模型适配仓库管理员并且仓库硬件类型为npu,才可以启动模型性能测试。

- 点击模型评测tab栏,进入模型评测页面。
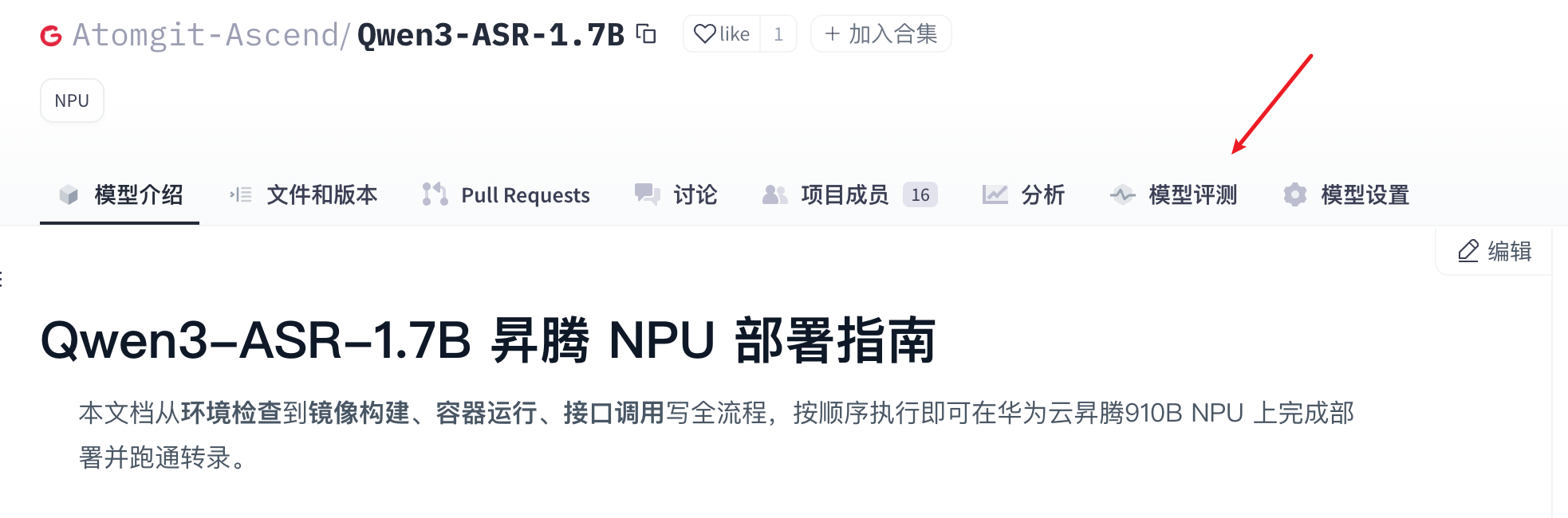
- 在模型评测的页面,点击“性能测试”的tab,选择模型的权重文件,然后单击“立即测试”,发起性能测试。
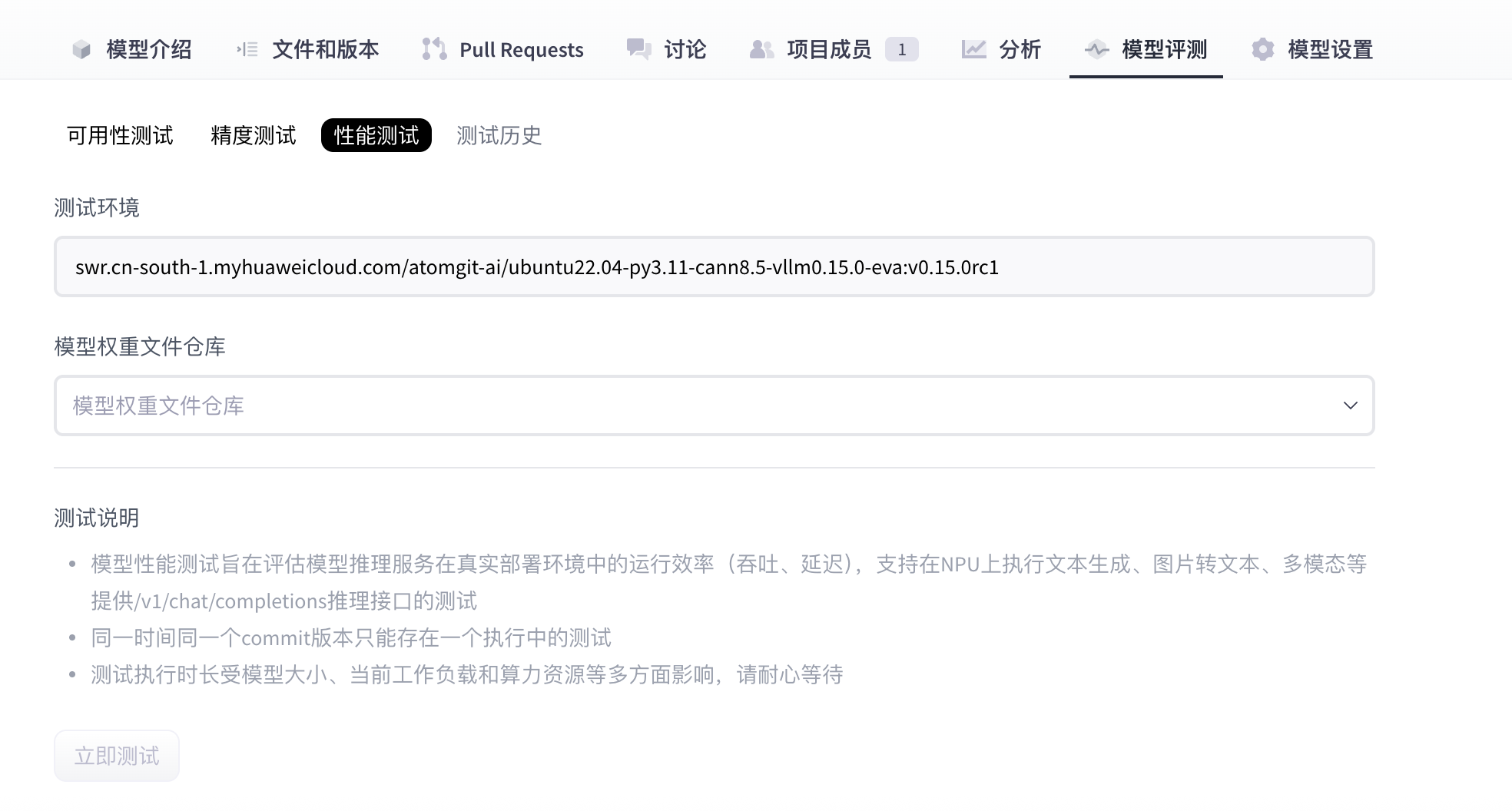
- 等待性能测试用例执行完成。
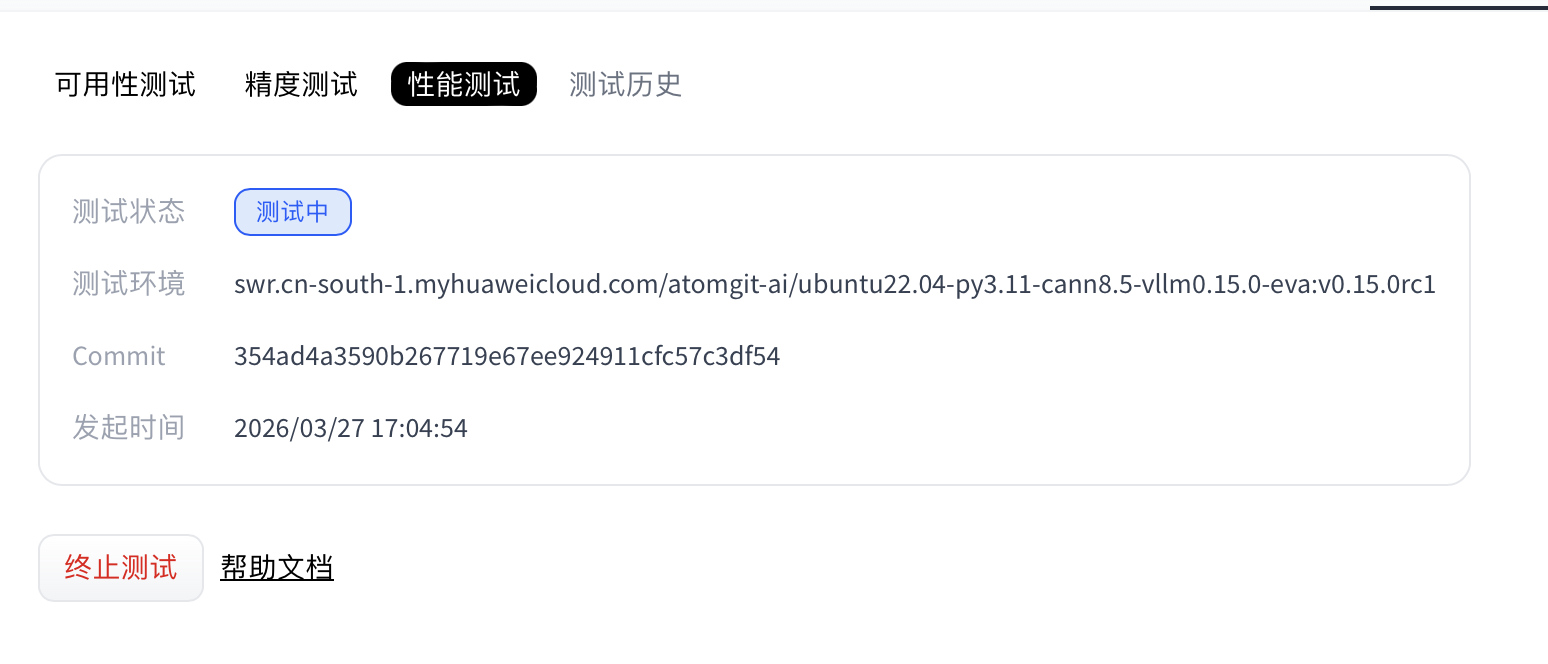
- (可选) 当模型处于“测试中”时,用户可以单击“终止测试”手动停止性能测试。
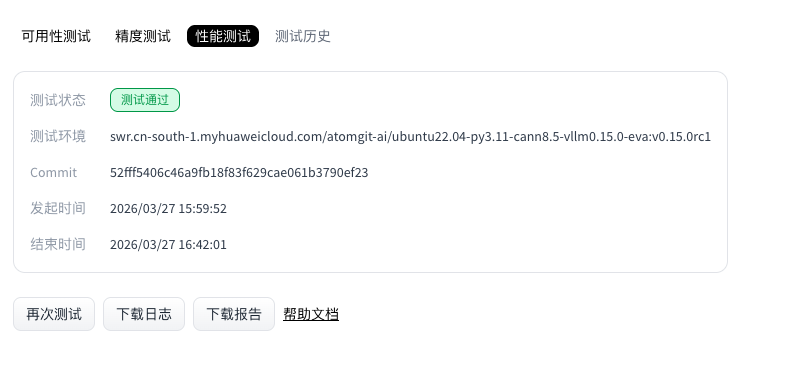
- 当性能评测执行完成后,在“性能测试”区域显示测试状态,并提供测试日志和评测报告下载。
模型性能测试运行脚本
模型性能测试脚本以deploy.sh为入口。脚本编写请严格遵照本文档的规范。
模型性能测试的适配仓库须包含以下两个文件:
- requirements.txt:该脚本运行需配置的相应module ,如果没有需要安装的依赖,则无需创建 (非必须)。
- deploy.sh: 模型评测服务基于该脚本安装依赖和启动此模型适配项目 (必须)。
文件位置
requirements.txt和deploy.sh必须位于仓库根目录下。
requirements.txt文件(可选)
请设置NPU下运行该脚本需要配置的对应依赖,Torch_npu、Cann和Python根据选择的框架版本由环境提供,因此在requirements.txt中不需要重复上述依赖的添加(可能会导致依赖安装冲突异常)。库的依赖脚本格式示例如下:
transformers==4.37.0
accelerate==0.27.2
如果不需要添加任何依赖,该.txt文件可不提供,测试任务会跳过依赖安装。
deploy.sh文件
该文件是一个执行启动模型适配推理的shell脚本,该推理脚本运行方式无严格限制,以下为脚本规范。
执行安装依赖编写示例(可选)
python3 -m pip install --upgrade pip setuptools wheel
构造执行脚本所需要的入参
模型权重由自动化测试执行侧根据模型评测发起时页面选择模型权重仓库,在执行测试的时候下载。在shell脚本中,如果需要传入权重路径,可以通过环境变量"$MODEL_PATH"获取权重文件所在的path路径。如vllm启动项目,则传入模型path路径示例如下:
vllm serve "$MODEL_PATH" --trust-remote-code --tensor-parallel-size 1 --dtype float16 --max-num-seqs 4 --gpu-memory-utilization 0.95
适配代码编写要求
适配推理代码需要提供标准的openapi推理接口,并且启动http server服务的端口必须为:8000。模型评测服务会根据选择的模型权重文件任务类型调用对应的推理接口进行模型评测 目前已经支持评测任务类型如下:
| 任务类型 | 任务编码 | 推理接口path |
|---|---|---|
| 文本生成 | text-generation | /v1/chat/completions |
| 图片转文本 | image-text-to-text | /v1/chat/completions |
| 多模态 | any-to-any | /v1/chat/completions |
注:模型性能测试服务依赖请求/v1/chat/completions进行测试,如果不存在此推理接口,会导致精度评测任务失败。
模型权重文件大小限制
- 大小上限:100GB
- 限制说明:适配模型权重文件存储大小不得超出上限。
- 影响范围:若超出限制,将触发模型权重文件下载失败,直接导致模型评测任务失败。
全流程代码示例
deploy.sh
- vllm适配验证示例:
#!/bin/sh
set -e
echo "=== MODEL_PATH set to: $MODEL_PATH ==="
vllm serve "$MODEL_PATH" --trust-remote-code --tensor-parallel-size 1 --dtype float16 --max-num-seqs 4 --gpu-memory-utilization 0.95
注:上面示例为vllm启动方式,无需设置–served-model-name,模型评测服务会自动使用模型权重的path作为serverd-model-name.
性能测试报告
性能评测执行成功以后,下载精度测试报告,解压缩以后,包含以下文件夹:configs、logs、performance,
最终生成的目录结构如下:
ee9480acbbac4d4aa190a124d5ddf39c/
├── configs # 自动存储的所有已转储配置文件
├── logs # 执行过程中日志,命令中如果加--debug,不会有过程日志落盘(都直接打印出来了)
│ └── performance/ # 推理阶段的日志文件
└── performance # 性能测评结果
│ └── vllm-api-stream-chat/ # “服务化模型配置”名称,对应模型任务配置文件中models的 abbr参数
│ ├── gsm8kdataset.csv # 单次请求性能输出(CSV),与性能结果打屏中的Performance Parameters表格一致
│ ├── gsm8kdataset.json # 端到端性能输出(JSON),与性能结果打屏中的Common Metric表格一致
│ ├── gsm8kdataset_details.json # 全量打点日志(JSON)
│ └── gsm8kdataset_plot.html # 请求并发可视化报告(HTML)
查看性能结果
性能结果打印在评测日志中的示例如下:
03/26 20:22:24 - AISBench - INFO - Performance Results of task: vllm-api-stream-chat/gsm8kdataset:
╒══════════════════════════╤═════════╤══════════════════╤══════════════════╤══════════════════╤══════════════════╤══════════════════╤══════════════════╤══════════════════╤══════╕
│ Performance Parameters │ Stage │ Average │ Min │ Max │ Median │ P75 │ P90 │ P99 │ N │
╞══════════════════════════╪═════════╪══════════════════╪══════════════════╪══════════════════╪══════════════════╪══════════════════╪══════════════════╪══════════════════╪══════╡
│ E2EL │ total │ 2048.2945 ms │ 1729.7498 ms │ 3450.96 ms │ 2491.8789 ms │ 2750.85 ms │ 3184.9186 ms │ 3424.4354 ms │ 8 │
├──────────────────────────┼─────────┼──────────────────┼──────────────────┼──────────────────┼──────────────────┼──────────────────┼──────────────────┼──────────────────┼──────┤
│ TTFT │ total │ 50.332 ms │ 50.6244 ms │ 52.0585 ms │ 50.3237 ms │ 50.5872 ms │ 50.7566 ms │ 50 .0551 ms │ 8 │
├──────────────────────────┼─────────┼──────────────────┼──────────────────┼──────────────────┼──────────────────┼──────────────────┼──────────────────┼──────────────────┼──────┤
│ TPOT │ total │ 10.6965 ms │ 10.061 ms │ 10.8805 ms │ 10.7495 ms │ 10.7818 ms │ 10.808 ms │ 10.8582 ms │ 8 │
├──────────────────────────┼─────────┼──────────────────┼──────────────────┼──────────────────┼──────────────────┼──────────────────┼──────────────────┼──────────────────┼──────┤
│ ITL │ total │ 10.6965 ms │ 7.3583 ms │ 13.7707 ms │ 10.7513 ms │ 10.8009 ms │ 10.8358 ms │ 10.9322 ms │ 8 │
├──────────────────────────┼─────────┼──────────────────┼──────────────────┼──────────────────┼──────────────────┼──────────────────┼──────────────────┼──────────────────┼──────┤
│ InputTokens │ total │ 1512.5 │ 1481.0 │ 1566.0 │ 1511.5 │ 1520.25 │ 1536.6 │ 1563.06 │ 8 │
├──────────────────────────┼─────────┼──────────────────┼──────────────────┼──────────────────┼──────────────────┼──────────────────┼──────────────────┼──────────────────┼──────┤
│ OutputTokens │ total │ 287.375 │ 200.0 │ 407.0 │ 280.0 │ 322.75 │ 374.8 │ 403.78 │ 8 │
├──────────────────────────┼─────────┼──────────────────┼──────────────────┼──────────────────┼──────────────────┼──────────────────┼──────────────────┼──────────────────┼──────┤
│ OutputTokenThroughput │ total │ 115.9216 token/s │ 107.6555 token/s │ 116.5352 token/s │ 117.6448 token/s │ 118.2426 token/s │ 118.3765 token/s │ 118.6388 token/s │ 8 │
╘══════════════════════════╧═════════╧══════════════════╧══════════════════╧══════════════════╧══════════════════╧══════════════════╧══════════════════╧══════════════════╧══════╛
╒══════════════════════════╤═════════╤════════════════════╕
│ Common Metric │ Stage │ Value │
╞══════════════════════════╪═════════╪════════════════════╡
│ Benchmark Duration │ total │ 19897.8505 ms │
├──────────────────────────┼─────────┼────────────────────┤
│ Total Requests │ total │ 8 │
├──────────────────────────┼─────────┼────────────────────┤
│ Failed Requests │ total │ 0 │
├──────────────────────────┼─────────┼────────────────────┤
│ Success Requests │ total │ 8 │
├──────────────────────────┼─────────┼────────────────────┤
│ Concurrency │ total │ 0.9972 │
├──────────────────────────┼─────────┼────────────────────┤
│ Max Concurrency │ total │ 1 │
├──────────────────────────┼─────────┼────────────────────┤
│ Request Throughput │ total │ 0.4021 req/s │
├──────────────────────────┼─────────┼────────────────────┤
│ Total Input Tokens │ total │ 12100 │
├──────────────────────────┼─────────┼────────────────────┤
│ Prefill Token Throughput │ total │ 17014.3123 token/s │
├──────────────────────────┼─────────┼────────────────────┤
│ Total generated tokens │ total │ 2299 │
├──────────────────────────┼─────────┼────────────────────┤
│ Input Token Throughput │ total │ 608.7438 token/s │
├──────────────────────────┼─────────┼────────────────────┤
│ Output Token Throughput │ total │ 115.7835 token/s │
├──────────────────────────┼─────────┼────────────────────┤
│ Total Token Throughput │ total │ 723.5273 token/s │
╘══════════════════════════╧═════════╧════════════════════╛
03/26 20:22:24 - AISBench - INFO - Performance Result files locate in outputs/default/20250605_202220/performances/vllm-api-stream-chat.
性能测评结果说明
性能测评结果包括单个推理请求性能输出结果和端到端性能输出结果,参数说明如下:
单个推理请求性能输出结果
部分统计指标解释如下所示:
- P75 / P90 / P99:以 TPOT 为例,表示所有请求的 TPOT 值分别处于第 75、90、99 百分位的性能表现。
- E2EL(End-to-End Latency):单个请求从发送到接收全部响应的总时延。
- TTFT(Time To First Token):首个 Token 返回的时延。
- TPOT(Time Per Output Token):输出阶段每个 Token 的平均生成时延(不含首个 Token)。
- ITL(Inter-token Latency):相邻 Token 间的平均间隔时延(不含首个 Token)。
- InputTokens:请求的输入 Token 数量。
- OutputTokens:请求生成的输出 Token 数量。
- OutputTokenThroughput:输出 Token 的吞吐率(Token/s)。
- Tokenizer:Tokenizer 编码耗时。
- Detokenizer:Detokenizer 解码耗时。
| Performance Parameters | Stage | Average | Max | Min | Median | P75 | P90 | P99 | N |
|---|---|---|---|---|---|---|---|---|---|
| E2EL | 统计此参数的阶段 | 平均请求时延 | 最大请求时延 | 最小请求时延 | 请求时延中位数 | 请求时延75分位值 | 请求时延90分位值 | 请求时延99分位值 | 测试数据量,来源于输入参数 |
| TTFT | 统计此参数的阶段 | 首个token平均时延 | 首个token最大时延 | 首个token最小时延 | 首个token中位数时延 | 首个token75分位时延 | 首个token90分位时延 | 首个token99分位时延 | 测试数据量,来源于输入参数 |
| TPOT | 统计此参数的阶段 | Decode阶段平均时延 | 最大Decode阶段时延 | 最小Decode阶段时延 | Decode阶段中位数时延 | 75分位Decode阶段时延 | 90分位每条请求Decode阶段平均时延 | 99分位Decode阶段时延 | 测试数据量,来源于输入参数 |
| ITL | 统计此参数的阶段 | token间平均时延 | token间最大时延 | token间最小时延 | token间中位数时延 | token间75分位时延 | token间90分位时延 | token间99分位时延 | 测试数据量,来源于输入参数 |
| InputTokens | 统计此参数的阶段 | 输入token平均长度 | 最大输入token长度 | 最小输入token长度 | 输入token中位数长度 | 75分位输入token长度 | 90分位输入token长度 | 99分位输入token长度 | 测试数据量,来源于输入参数 |
| OutputTokens | 统计此参数的阶段 | 输出token平均长度 | 最大输出token长度 | 最小输出token长度 | 输出token中位数长度 | 75分位输出token长度 | 90分位输出token长度 | 99分位输出token长度 | 测试数据量,来源于输入参数 |
| OutputTokenThroughput | 统计此参数的阶段 | 平均输出吞吐 | 最大输出吞吐 | 最小输出吞吐 | 中位数输出吞吐 | 输出吞吐75分位 | 输出吞吐90分位 | 输出吞吐99分位 | 测试数据量,来源于输入参数 |
端到端性能输出结果
| 参数 | 说明 |
|---|---|
| Benchmark Duration | 测试任务的总执行时间 |
| Total Requests | 请求总数量 |
| Failed Requests | 请求失败数量(包含无响应或响应为空) |
| Success Requests | 成功返回的请求数量(包括空响应与非空响应) |
| Concurrency | 实际平均并发数 |
| Max Concurrency | 配置的最大并发数 |
| Request Throughput | 请求级吞吐率(请求数/秒) |
| Total Input Tokens | 所有请求的总输入 Token 数 |
| Prefill Token Throughput | Prefill 阶段的 Token 吞吐率 |
| Total Output Tokens | 所有请求生成的总输出 Token 数 |
| Input Token Throughput | 输入 Token 吞吐率 |
| Output Token Throughput | 输出 Token 吞吐率 |
| Total Token Throughput | 总 Token 吞吐率(输入 + 输出) |
性能测试可视化并发图使用说明
该并发图用于展示性能测评过程中的详细推理耗时,包括:
- 请求力度耗时展示:每条请求的详细处理耗时,包含Prefill 阶段耗时、Decode 阶段耗时以及请求完整耗时
- 实时并发数展示:反映测试过程中的并发变化趋势,帮助判断请求调度与系统吞吐能力。
核心功能
- 精细化耗时分析:可对每条请求的处理过程进行拆解,识别性能瓶颈是否集中在 prefill 或 decode 阶段。
- 并发动态可视化:展示整个测试期间的并发水平波动,辅助评估系统在高并发压力下的稳定性与响应效率。
- 支持大规模请求回放:适用于高压测试,分析模型或服务在持续负载下的表现。
使用场景
- 性能调优:识别瓶颈点,为模型推理服务的延迟优化、并发控制、批量处理策略调整提供数据支持。
- 推理服务压测验证:对部署后的服务进行压力测试,确保在目标并发场景下性能达标。
- 部署方案评估:对比不同模型、不同部署方式(如本地 vs 服务化)在相同负载下的响应表现。
数据生成方式: 性能测试将自动生成一份 HTML 可视化报告。使用任意主流浏览器打开该文件,即可交互式查看每条请求的详细耗时信息和全程并发曲线。
性能报告文件查看
1. 视图控制
鼠标滑动至图的右上角可显示导航栏
导航栏说明
从左到右按顺序
| 名称 | 符号 | 作用 | 图例 |
|---|---|---|---|
| Download | 照相机 | 将当前视图截屏并保存为png格式 |  |
| Zoom | 放大镜 | 开启Zoom模式,详见下表 鼠标操作说明 中的 鼠标拖拽画布 行 |  |
| Pan | 正十字 | 开启Pan模式,详见下表 鼠标操作说明 中的 鼠标拖拽画布 行 |  |
| Zoom in | 加号 | 以当前视图为中心,等比例同时放大上下两张图 |  |
| Zoom out | 减号 | 以当前视图为中心,等比例同时缩小上下两张图 |  |
| Autoscale | 斜十字 + 四角外框 | 根据数据规模,重置全图 |  |
| Reset axes | 房屋 | 根据初始设置,重置全图 |  |
2. 数据查看
- 参考样例
- 全图总览
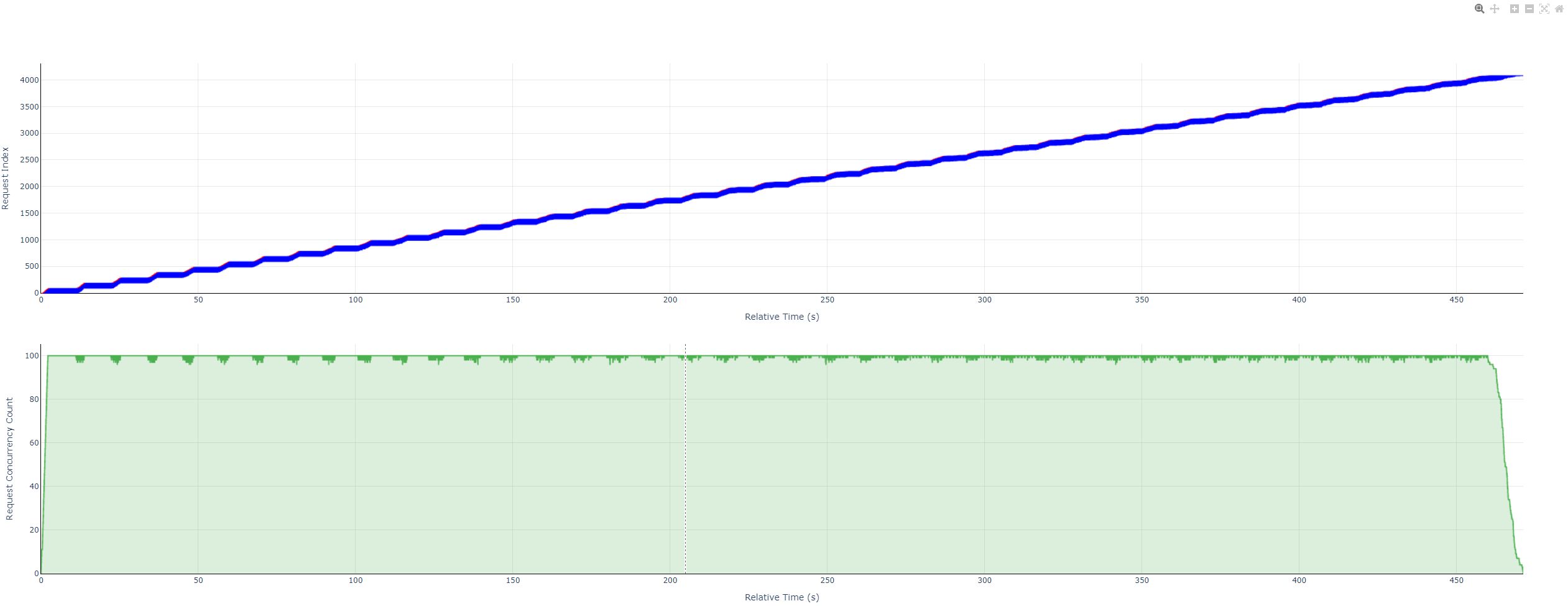
- 请求线段图
- 带Decode阶段图例

- 不带Decode阶段图例
- 带Decode阶段图例
- 并发阶梯图
- 全图总览
- 图例说明与计算
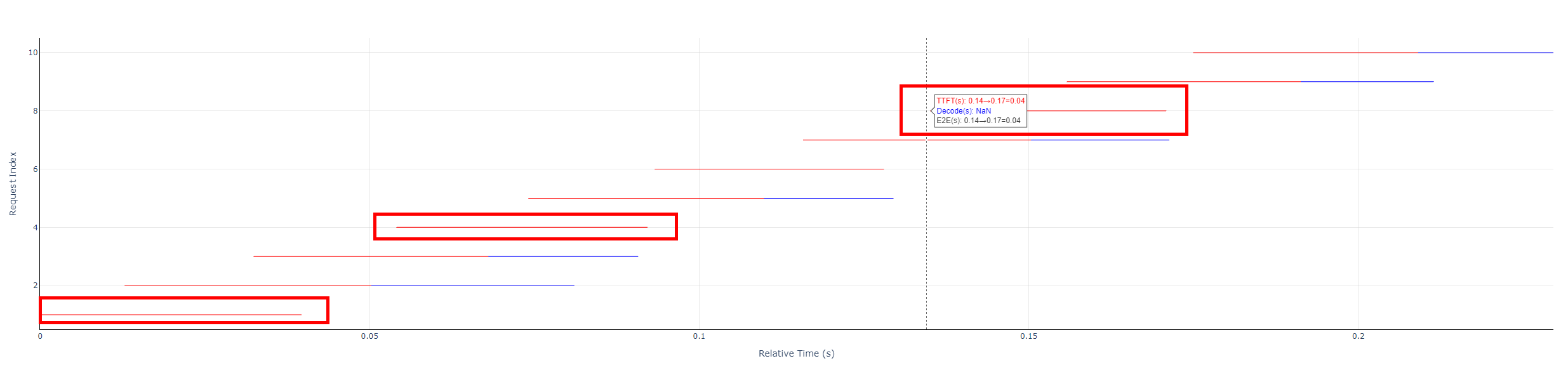
- 请求线段图
- 每条水平线段:由红、蓝两部分,或只由红色部分组成,表示一条请求的E2EL
- 红色线段:TTFT,即首Token时延
- 蓝色线段:Decode, 即非首Token时延
- 值的计算
- TTFT =
prefill_latency - Decode =
end_time- (start_time+prefill_latency) - End-to-End Latency(E2EL) =
end_time-start_time
- TTFT =
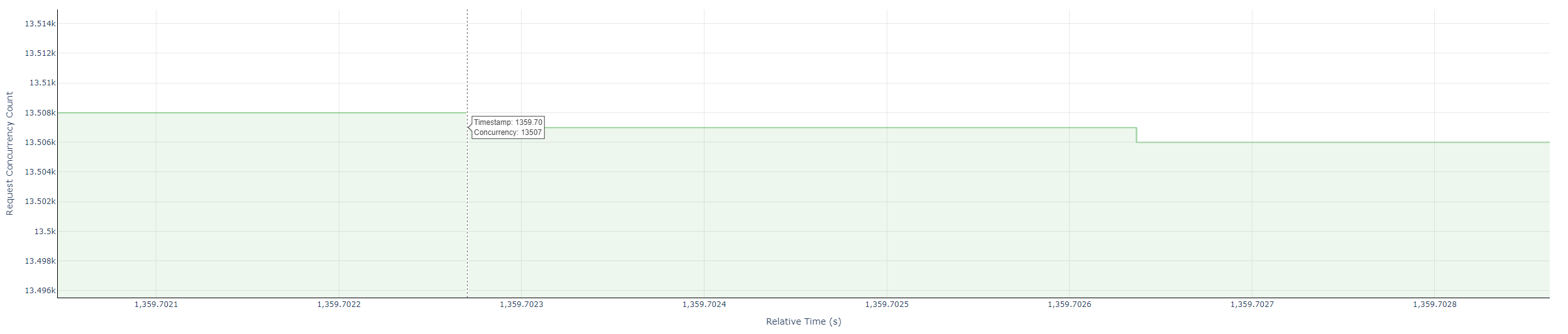
- 并发阶梯图
- 绿色线段:表示随着时间变化而变化的实时请求并发数
- 值的计算:截取当前时间点的请求数量
- 请求线段图
- 悬停文本框
- 请求线段图:光标悬停在每条请求线段最开始的数据点附近,显示:首Token时延(TTFT)、非首Token时延(Decode)、该请求总时长(E2EL)
- 并发阶梯图:光标悬停在新事件的转折拐角点,显示:时间戳(Time)、并发数(Concurrency)
- 坐标轴说明
- 请求线段图:
- 横坐标:相对时间线,起始点:0,单位:s
- 纵坐标:请求索引,起始点:1
- 并发阶梯图:
- 横坐标:相对时间线,起始点:0,单位:s
- 纵坐标:请求并发个数,起始点:1
- 请求线段图:
注:以上性能测试结果说明资料来源: AISBench官网