模型微调流程
Qwen3-4B模型微调完整指南
本文档详细介绍了使用Qwen3-4B-Thinking-2507模型进行微调的完整流程,从环境搭建到模型部署的一站式指南。
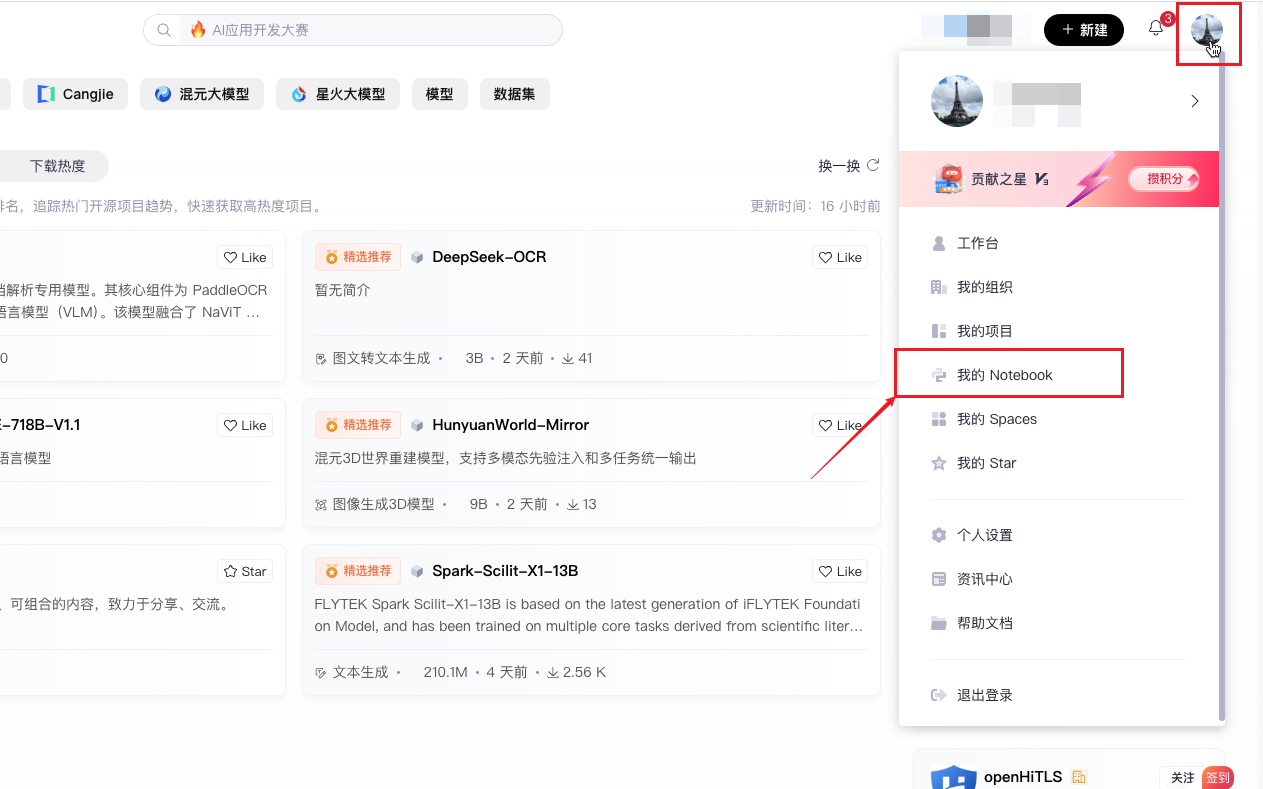
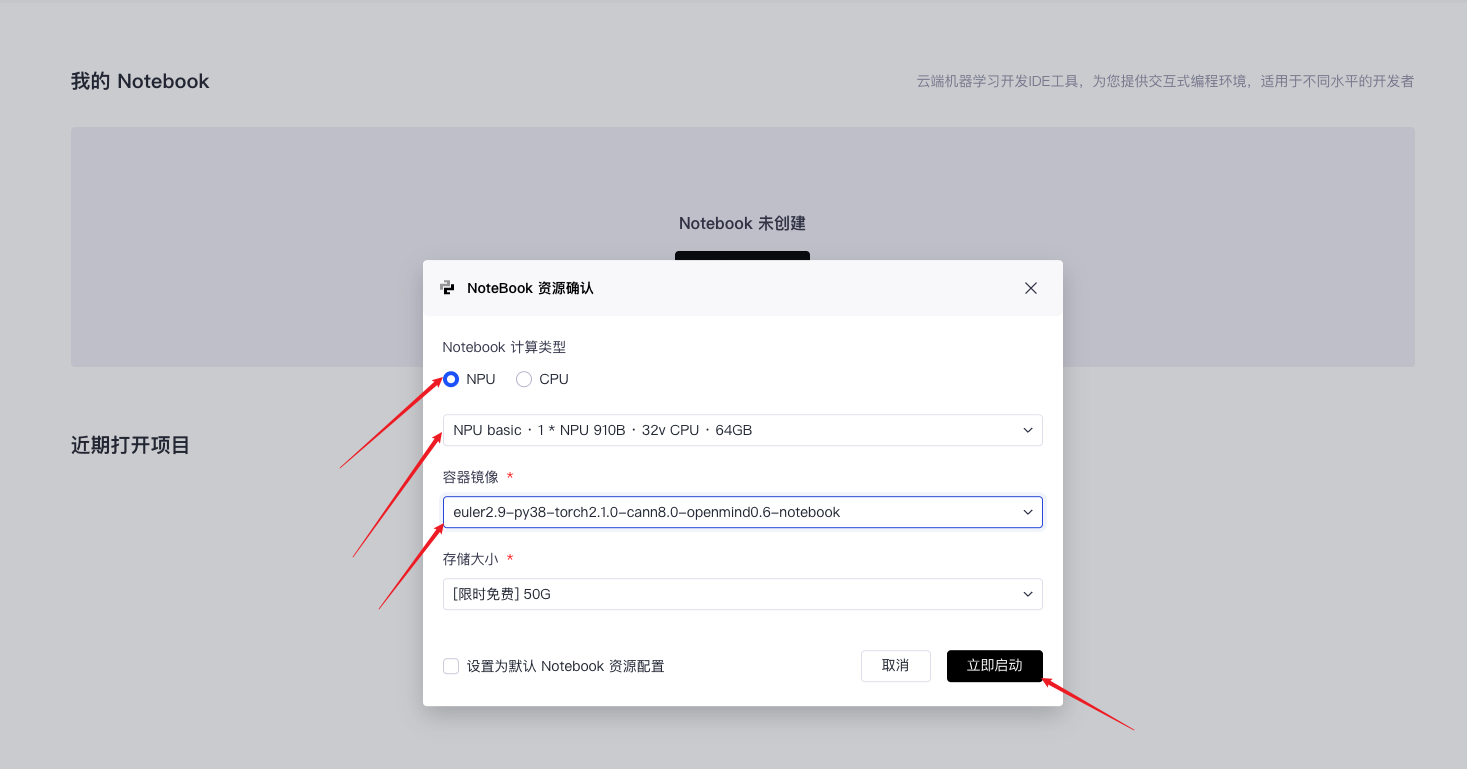
首先启动Notebook服务
按照以下界面操作启动Jupyter Notebook:
目录
1. 环境安装
1.1 安装Miniconda
Windows系统:
- 访问Miniconda官网下载安装包
- 运行安装程序,按提示完成安装
- 重新打开命令提示符
macOS/Linux系统:
# macOS
brew install miniconda
# Linux
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh
source ~/.bashrc
1.2 创建Python环境
# 创建并激活环境
conda create -n myenv python=3.10
conda activate myenv
# 验证安装
python --version
1.3 配置Jupyter Notebook
# 安装Jupyter
pip install jupyter ipykernel ipywidgets
# 注册内核
python -m ipykernel install --user --name=myenv --display-name="Python (myenv)"
# 启动Notebook
jupyter notebook
重要提示:在Notebook中选择 Python (myenv) 内核
1.4 安装依赖包
在激活的myenv环境中运行:
# 一键安装所有依赖
pip install datasets==2.21.0 addict swanlab accelerate transformers numpy==1.24.4 scipy openmind-hub modelscope torch pandas torch_npu==2.5.1
1.5 环境验证
在Jupyter Notebook第一个cell中运行:
import sys
import os
# 配置环境变量
os.environ["OPENMIND_HUB_ENDPOINT"] = "https://hub.gitcode.com"
# 验证主要包
packages = ['torch', 'transformers', 'datasets', 'swanlab', 'openmind_hub']
for pkg in packages:
try:
module = __import__(pkg)
print(f"✓ {pkg}: {getattr(module, '__version__', 'installed')}")
except ImportError:
print(f"✗ {pkg}: 未安装")
2. 模型下载
2.1 下载Qwen3-4B-Thinking-2507
from openmind_hub import snapshot_download
import os
# 设置环境变量
os.environ["OPENMIND_HUB_ENDPOINT"] = "https://hub.gitcode.com"
# 下载模型(注意路径格式)
snapshot_download(
"hf_mirrors%2FQwen/Qwen3-4B-Thinking-2507",
local_dir='./model/Qwen3-4B-Thinking-2507'
)
下载完成后,模型将保存在 ./model/Qwen3-4B-Thinking-2507/ 目录中。
3. 数据集准备
3.1 加载和处理数据
from modelscope.msdatasets import MsDataset
import json
import random
# 设置随机种子
random.seed(42)
# 加载医疗数据集
ds = MsDataset.load('krisfu/delicate_medical_r1_data', subset_name='default', split='train')
data_list = list(ds)
# 数据分割(9:1)
random.shuffle(data_list)
split_idx = int(len(data_list) * 0.9)
train_data = data_list[:split_idx]
val_data = data_list[split_idx:]
# 保存数据
for data, filename in [(train_data, 'train.jsonl'), (val_data, 'val.jsonl')]:
with open(filename, 'w', encoding='utf-8') as f:
for item in data:
json.dump(item, f, ensure_ascii=False)
f.write('\n')
print(f"训练集:{len(train_data)} 条,验证集:{len(val_data)} 条")
4. 模型微调
4.1 SwanLab配置
SwanLab用于监控训练过程:
- 访问SwanLab官网注册获取API Key
- 在Notebook中登录:
import swanlab
swanlab.login(api_key="YOUR_API_KEY", save=True)
4.2 准备训练代码
import json
import pandas as pd
import torch
import torch_npu
from datasets import Dataset
from transformers import AutoTokenizer, AutoModelForCausalLM, TrainingArguments, Trainer, DataCollatorForSeq2Seq
import os
# 项目配置
os.environ["SWANLAB_PROJECT"] = "qwen3-sft-medical"
PROMPT = "你是一个医学专家,你需要根据用户的问题,给出带有思考的回答。"
MAX_LENGTH = 2048
# 数据转换函数
def dataset_jsonl_transfer(origin_path, new_path):
messages = []
with open(origin_path, "r") as file:
for line in file:
data = json.loads(line)
output = f"<think>{data['think']}</think> \n {data['answer']}"
message = {
"instruction": PROMPT,
"input": data["question"],
"output": output,
}
messages.append(message)
with open(new_path, "w", encoding="utf-8") as file:
for message in messages:
file.write(json.dumps(message, ensure_ascii=False) + "\n")
# 预处理函数
def process_func(example):
instruction = tokenizer(
f"<|im_start|>system\n{PROMPT}<|im_end|>\n<|im_start|>user\n{example['input']}<|im_end|>\n<|im_start|>assistant\n",
add_special_tokens=False,
)
response = tokenizer(f"{example['output']}", add_special_tokens=False)
input_ids = instruction["input_ids"] + response["input_ids"] + [tokenizer.pad_token_id]
attention_mask = instruction["attention_mask"] + response["attention_mask"] + [1]
labels = [-100] * len(instruction["input_ids"]) + response["input_ids"] + [tokenizer.pad_token_id]
# 截断处理
if len(input_ids) > MAX_LENGTH:
input_ids = input_ids[:MAX_LENGTH]
attention_mask = attention_mask[:MAX_LENGTH]
labels = labels[:MAX_LENGTH]
return {"input_ids": input_ids, "attention_mask": attention_mask, "labels": labels}
4.3 加载模型和数据
# 加载模型
tokenizer = AutoTokenizer.from_pretrained(
"./model/Qwen3-4B-Thinking-2507",
use_fast=False,
trust_remote_code=True
)
model = AutoModelForCausalLM.from_pretrained(
"./model/Qwen3-4B-Thinking-2507",
torch_dtype=torch.bfloat16
).to("npu:0")
model.enable_input_require_grads()
# 处理数据集
dataset_jsonl_transfer("train.jsonl", "train_format.jsonl")
dataset_jsonl_transfer("val.jsonl", "val_format.jsonl")
# 创建训练数据
train_df = pd.read_json("train_format.jsonl", lines=True)
train_dataset = Dataset.from_pandas(train_df).map(process_func, remove_columns=train_df.columns)
eval_df = pd.read_json("val_format.jsonl", lines=True)
eval_dataset = Dataset.from_pandas(eval_df).map(process_func, remove_columns=eval_df.columns)
4.4 训练配置和开始训练
# 训练参数
args = TrainingArguments(
output_dir="./output/Qwen3-4B",
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
gradient_accumulation_steps=4,
eval_strategy="steps",
eval_steps=100,
logging_steps=10,
num_train_epochs=2,
save_steps=400,
learning_rate=1e-4,
save_on_each_node=True,
gradient_checkpointing=True,
report_to="swanlab",
run_name="qwen3-4B-medical",
)
# 创建训练器
trainer = Trainer(
model=model,
args=args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True),
)
# 开始训练
trainer.train()
5. 效果评估
5.1 推理测试
def predict(messages, model, tokenizer):
device = "npu:0"
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(model_inputs.input_ids, max_new_tokens=MAX_LENGTH)
generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)]
return tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
# 测试样例
test_df = pd.read_json("val_format.jsonl", lines=True)[:3]
test_results = []
for _, row in test_df.iterrows():
messages = [
{"role": "system", "content": row['instruction']},
{"role": "user", "content": row['input']}
]
response = predict(messages, model, tokenizer)
result = f"问题: {row['input']}\n回答: {response}\n{'='*50}"
test_results.append(swanlab.Text(result))
print(result)
# 记录到SwanLab
swanlab.log({"测试结果": test_results})
swanlab.finish()
5.2 评估指标
微调后的模型应具备以下能力:
- 理解医疗专业问题
- 提供结构化思考过程(
<think>标签) - 给出准确的医疗建议
- 保持专业的医学用语
6. 模型部署
6.1 上传到AtomGit
方式1:使用OpenMind Hub
from openmind_hub import push_to_hub
push_to_hub(
repo_id="your_username/qwen3-4b-medical-finetuned",
folder_path="./output/Qwen3-4B",
token="your_gitcode_token"
)
方式2:Git命令
cd ./output/Qwen3-4B
git init
git remote add origin https://gitcode.com/your_username/qwen3-4b-medical-finetuned.git
git add .
git commit -m "Add fine-tuned Qwen3-4B medical model"
git push -u origin main
6.2 创建模型说明
创建 README.md 文件描述模型:
# Qwen3-4B医疗微调模型
## 模型信息
- **基础模型**: Qwen3-4B-Thinking-2507
- **训练数据**: 医疗问答数据集
- **训练轮数**: 2轮
- **学习率**: 1e-4
## 使用方法
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("your_username/qwen3-4b-medical-finetuned")
model = AutoModelForCausalLM.from_pretrained("your_username/qwen3-4b-medical-finetuned")
总结
本指南涵盖了Qwen3-4B医疗模型微调的完整流程:
- 环境搭建 → Conda环境 + Jupyter配置
- 模型准备 → 下载预训练模型
- 数据处理 → 医疗数据集预处理
- 模型训练 → 微调训练配置
- 效果验证 → 推理测试评估
- 模型发布 → 上传到AtomGit平台
常见问题
Q: 训练过程中内存不足怎么办?
A: 减少 per_device_train_batch_size 或增加 gradient_accumulation_steps
Q: 如何选择不同的内核?
A: 在Jupyter中选择 Kernel → Change kernel → Python (myenv)
Q: SwanLab显示异常怎么办? A: 检查API Key是否正确,网络是否正常
Q: 模型效果不满意怎么优化? A: 调整学习率、增加训练轮数、优化数据质量
需要技术支持?请参考各章节详细说明或联系技术团队。